cross entropy
Cross Entropy에 대한 설명.
entropy(엔트로피)
엔트로피는 무질서, 임의성 또는 불확실성의 상태와 가장 일반적으로 관련된 과학적 개념이자 측정 가능한 물리적 특성이다.(wikipedia) 정보이론 측면에서 살펴본다. 불확실성, 무질서의 상태를 측정하기 때문에 엔트로피 값이 클 수록 데이터가 분류가 잘 되어 있지 않은 상태이고 엔트로피 값이 작을 수록 데이터가 잘 분류되어 있는 것이다.
entropy 공식 (\(log_2\) 는 \(lg2\)로 간략히.)
엔트로피 공식은 n개의 가능한 사건으로 일반화될 수 있다. 어떤 사건 A가 발생할 확률을 \(p\) 라고 할 때 엔트로피 공식은 다음과 같다. \(h(x) = -\sum_{i=1}^n (p_i \log_2(p_i))\) \(lg_2(p)\)에 \(p\)를 곱한 후 모두 더한 값에 -(minus)를 취한다.
엔트로피는 특성 사건에 대해 알기 위해 얻어야 하는 정보의 평균 비트 수인데, 사건의 결과를 알기 위해서는 불확실성을 0으로 줄여야 한다(즉, 확실성을 1로). 어떤 사건 A가 발생할 확률이 p라면 그 결과를 안다는 것은 불확실성을 \(\frac{1}{p}\) 만큼 줄이는 것을 의미한다. 따라서 사건 결과에 대해 알기 위해서는 \(log\frac{1}{p}\) 비트 수가 필요하며 이는 \(-lg(p)\)와 같다. 이것은 A가 발생할 때의 엔트로피 값이다. 마찬가지로 A가 일어나지 않을 때의 엔트로피 값은 \(-log(1-p)\)이다. 확률 분포가 p를 갖는 Bernoulli 인 경우 사건의 평균 엔트로피는 \(-p * lg(p) -(1-p) * lg(1-p)\)이다.
엔트로피 VS 사건의 개수
사건의 개수가 많아진다면, 엔트로피는 높아짐을 직감할 수 있다. 확률이 같은 n개의 이벤트를 선택하고 확률 분포의 엔트로피를 계산해본다. \begin{equation} -n * \frac{1}{n} * lg\frac{1}{n} = lg(n) \end{equation} n이 증가할 수록 log함수적으로 엔트로피는 증가한다.
cross entropy(교차 엔트로피, 크로스 엔트로피)
사건의 결과에 대해 알아야 하는 평균 비트 수는 정보를 전송하는 데 사용되는 평균 비트 수와 다르다. 교차 엔트로피는 정보를 전송하는 데 사용되는 평균 비트 수이다. 교차 엔트로피는 항상 엔트로피보다 크거나 같다. 0.5, 0.25, 0.125 및 0.125의 확률로 네 가지 가능한 결과가 있는 확률 분포를 살펴본다. 이 정보를 전송하기 위해 2비트를 사용하면 교차 엔트로피는 2가 된다.
(1) 식에 대입하면, Entropy = 0.5 * lg(2) + 0.25 * lg(4) + 0.125 * lg(8) + 0.125 * lg(8) = 0.5 + 0.5 + 0.375 + 0.375 = 1.75이 도출된다. 즉 여기서 엔트로피는 1.75이다. 하지만, 정보의 전송을 위해 2bits를 사용했다. 즉 크로스 엔트로피는 2다. 이렇게 크로스 엔트로피와 엔트로피 간의 차이를 KL Divergence라고 한다.
모든 경우에 대한 정보를 전송하기 위해 2비트를 사용할 때 모든 이벤트에 대해 \(\frac{1}{2^2}\)의 확률을 가정한다. 따라서 실제 대 예측(또는 가정) 확률 분포는 다음과 같다. 0.5 vs 0.25, 0.25 vs 0.25, 0.125 vs 0.25 및 0.125 vs 0.25
첫 번째 이벤트 정보(1)를 전송하는 데 1비트를 사용하고 두 번째 이벤트 정보(10)를 전송하는 데 2비트를 사용하고, 세 번째 이벤트 정보(101)를 전송하는데 3비트, 네 번째 이벤트 정보(100)를 전송하는데 3비트를 사용했다면 최적의 메시지 길이를 사용했을 것이다. 따라서 서로 다른 이벤트에 대해 서로 다른 메시지 길이를 사용하는 경우 암묵적으로 확률 분포를 예측한다. 더 큰 교차 엔트로피 값을 얻을수록 예측 확률 분포가 실제 확률 분포에서 더 많이 벗어난다. 그것이 분류를 다룰 때 기계 학습에서 교차 엔트로피 손실이 사용되는 방식이다.
cross entropy
참고로 크로스 엔트로피는 아래와 같이 수식으로 표현할 수 있다. \begin{equation} h(p,q) = -\sum_{i=1}^n (q_i lg_2(p_i)) \end{equation}
h(p,q)는 오차를 의미함.
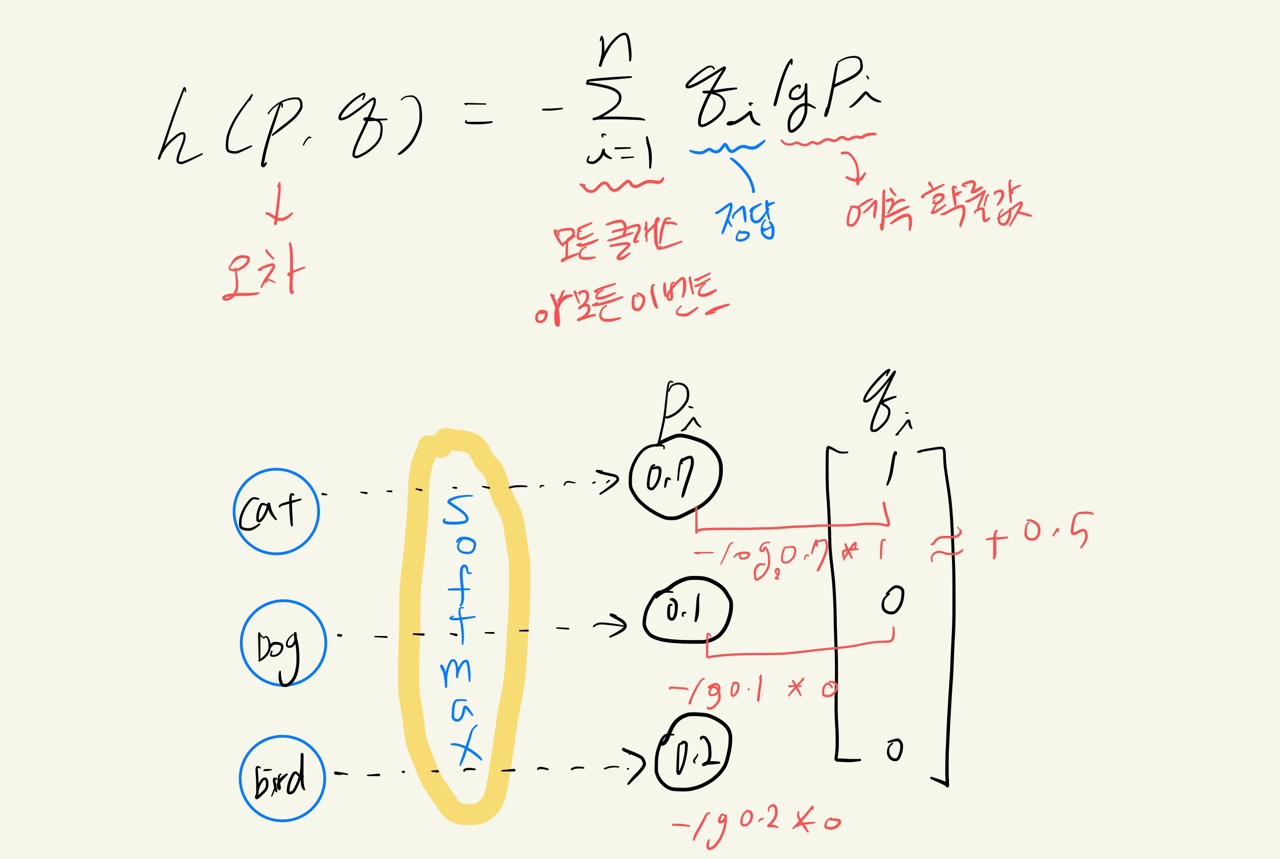
예측된 확률값(p)들이 [0, 0, 1] , [0, 1, 0]과 같이 완전히 틀리게 되면 lg(0)이 되므로 크로스 엔트로피는 무한대로 커진다.
고양이 개 분류 예시
가장 유명한 분류 문제 중 하나인 고양이와 개를 분류 문제에서는 이미지가 주어졌을 때 확률 분포를 예측하는 것이다. 실제 확률 분포는 레이블이고 로지스틱 함수는 예측된 확률 분포를 제공한다. 교차 엔트로피는 다음과 같은 방식으로 이 작업의 손실 함수로 사용한다.
개 이미지가 있고 확률 분포의 첫 번째 요소가 개에 대한 것이라고 가정한다. 그렇다면 실제 확률 분포는 다음과 같다. : [1, 0] 이제 로지스틱 함수가 [0.7, 0.3]의 확률 분포를 출력했다고 가정한다.
여기서 확률 0.7은 이미지가 개일 때 정보를 전송하는 데 사용되는 \(-lg(0.7)\) 비트 수를 의미. 따라서 교차 엔트로피는 \(-1 * lg(0.7) - 0 * lg(0.3) = 0.51\).
어떤 함수를 최소화하는 것은 그것의 양의 스칼라 배수를 최소화하는 것과 같기 때문에 기계 학습에서 손실을 정의하기 위해 2-base 로그 대신 자연 로그(또는 임의의 기본 로그)를 사용할 수 있다. 이렇게 될 경우, lg를 쓸 때 보다 더 작은 값이 나온다.
참고
https://squarecircle.be/entropy-and-disorder-the-fate-of-all-human-enterprises/
https://www.philgineer.com/2021/10/31.html
https://westshine-data-analysis.tistory.com/
https://www.youtube.com/watch?v=r3iRRQ2ViQM
특히 수식을 이해하는 데에는 아래 사이트가 도움 되었습니다. https://towardsdatascience.com/entropy-cross-entropy-and-kl-divergence-17138ffab87b