Crowded Scene에서 Human detector 구성하기.
yolo로 많은 사람 탐색하기.

YOLO를 사용해보자.
이전 글 에서는 사실상 inference 단계에서 confidence의 조절과 detection시 bbox를 사람만 치도록 만든 것에서 그쳤다.
하지만, 원하는 성능을 냈다고 볼 수 없었다. 너무 confidence parameter에 영향을 받기도 하고, 사람 무리를 하나의 사람으로 인식하는 문제가 있었기 때문.
그리고 비디오 영상 전체에 걸쳐서 강인하게 사람을 찾는 게 아니라서 아쉬웠음.
그래서 모델 자체를 학습해보기로 한다.

CrowdHuman Dataset
우선 Crowd Scene에 관련된 데이터셋을 찾는다. 이미지에 한 두 명의 사람이 아니라 적게는 수 명에서 많게는 수십명이 군집되어 있어서, 사람간의 가려짐 현상(Person Occlusion)이 발생하는 데이터셋이 적합하겠다. 구글링하니까 CrowdHuman(데이터셋 root source) 이 적합하다고 판단하였다.
썸네일에서 보면 알 수 있듯이, 사람의 full_body와 얼굴의 클래스로 분류할 수 있도록 annotation이 실제로 되어 있다. txt파일에 클래스와 bbox정보를 갖고 있음.
위 링크에서 paper와 데이터셋을 내려 받을 수 있고 절차가 매우 간단해서 좋다.
Data Pre-processing | Dataset Download from Roboflow
하지만, Yolo에서 학습을 위해서 데이터셋을 사용하기 위해서는 폴더 구조를 살짝 변형해줘야 한다.
후술하겠지만 이리저리 찾아보다가 발견한 바로는 이대로 따라야한다.
1
2
3
4
5
6
7
train: ../train/images #../train/images
val: ../valid/images #../valid/images
# test: ../test/images
nc: 1 # 분류할 클래스 수
# names: ['0', '1']
names: ['0'] # 분류 클래스 인덱스
이러한 처리가 미리 되어 있는 데이터셋이 참고링크3(데이터셋) 에서 구할 수 있어서 편하게 받았다.
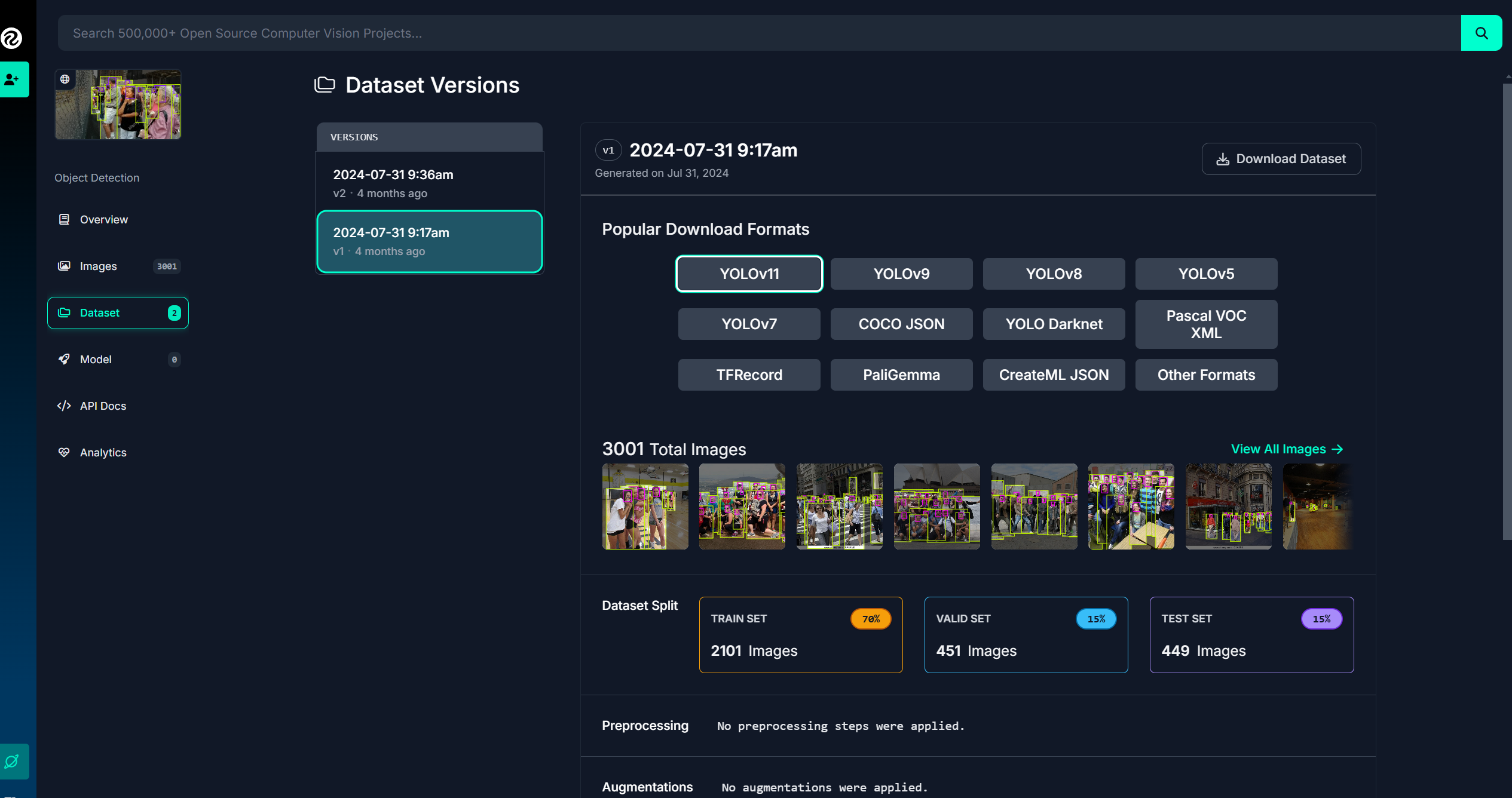
물론, 원본 데이터셋에 비하면 턱없이 부족한 3,000개 가량만 학습/평가 데이터셋으로 구분되어 있기 때문에 실제 데이터셋에서 학습을 위한 데이터셋을 마련하기 위해서는 데이터셋포맷변경(to_yolo) 에서 odgt를 txt로 변형해주는 파싱을 해준다. (추가 파싱필요할 수 있음. 폴더명 변형 등.)
아 그리고, 이게 중요한대 데이터셋은 0, 1 클래스로 구분하도록 되어 있다. 하지만 나는 사람 얼굴이 아니라 사람의 full body를 사람으로 인식하는 모델이 필요했으므로 데이터셋에서 1을 담당하는 얼굴 부분은 모두 제거하는 파싱 작업을 수행했다. 코드는 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import os
'''
CrowdHuman dataset에서 0,1 되어있는걸 0 클래스 정보만 남기고 다시 저장한다.
'''
def clean_labels(base_dir):
# 데이터셋의 경로 설정
subsets = ['train', 'valid'] # train, val, test 디렉토리 순회
for subset in subsets:
labels_dir = os.path.join(base_dir, subset, 'labels')
for label_file in os.listdir(labels_dir):
file_path = os.path.join(labels_dir, label_file)
if file_path.endswith('.txt'):
# 파일 읽기
with open(file_path, 'r') as file:
lines = file.readlines()
# 0 클래스만 필터링
filtered_lines = [line for line in lines if line.split()[0] == '0']
# 파일 덮어쓰기
with open(file_path, 'w') as file:
file.writelines(filtered_lines)
# 경로를 데이터셋 폴더로 설정
dataset_path = '/workspace/jin_space/Detector/dataset/CrowdHuman_'
clean_labels(dataset_path)
학습(Training)
데이터셋 준비와 yaml만 있으면 딱히 할게 더 없다. 그냥 yolo CLI 매뉴얼을 따라서 하이퍼파라미터 조정 등을 통해 학습을 진행하면 된다.
1
yolo detect train data=/workspace/jin_space/Detector/dataset/data.yaml model=yolo11x.pt epochs=220 imgsz=640 device=0
detect task에서 train을 하겠다는 것이고, yolo11x(가장큰모델)을 파인튜닝하겠다는 거다. epochs는 실험으로 5만 진행해보고 성능이 어느정도 나오길래 220으로 잡았다. GPU는 multi로 안쓰고 A100 한장만 쓰므로 device=0으로 지정해두었다.
python 명령어를 해도 좋지만, 그렇게 되면 engine에 있는 코드를 내가 건드려야해서(노답;) 그냥 yolo command를 썼는데 참 편하다. (대신 customizing에는 쥐약인 듯?)
결과
Inference할 때 역시 yolo에서 지정해둔 커맨드와 함수를 쓰면 편하긴 하지만 이건 bbox의 두께 등 커스터마이징이 필요해서 그냥 별도 함수를 만들어서 bbox를 그렸다. 해당 코드는 생략..
정량 평가는 의미가 없어서 그냥 정성 결과만 기록해둔다.

Reference
1) https://hashbrowny.tistory.com/68 : 참고링크1
2) https://minmiin.tistory.com/15 : 참고링크2
3) https://universe.roboflow.com/objectdetection-1gccs/crowdhuman-dtwxp/dataset/1 : 참고링크3(데이터셋)
4) https://gist.github.com/adujardin/62653118466962264aa0c6339c3e9cf5#file-crowdhuman_to_yolo-py : 데이터셋포맷변경(to_yolo)</br> 5) 데이터셋:
@article{shao2018crowdhuman,
title={CrowdHuman: A Benchmark for Detecting Human in a Crowd},
author={Shao, Shuai and Zhao, Zijian and Li, Boxun and Xiao, Tete and Yu, Gang and Zhang, Xiangyu and Sun, Jian},
journal={arXiv preprint arXiv:1805.00123},
year={2018}
}